The term has been around since it was first presented in a lecture on product life-cycle management in 2003, and is often described broadly as a virtual representation of a physical product. But is the term “digital twin” appropriate to use for CT data and 3D models derived from it?
Let’s consider it!
The term’s origins lie in the field of product life-cycle management and seems to be developed by industry and investors to monitor, manage, and improve a manufactured product throughout its life-cycle. In practice, there is no consolidated and consistent view of what a Digital Twin is (see this article for a literature review on Digital Twins). That in itself is enough to use caution.
In science, we typically do not create 3D representations of objects to improve or manage them (although in certain cases this may be the aim), but rather to understand, compare, or analyze them.
When the term first appeared in the literature, Digital Twins were described as consisting of three components:
- A physical product.
- A virtual representation of that product.
- The bi-directional data connections that feed data from the physical to the virtual representation, and information and processes from the virtual representation to the physical.
While volumetric CT data may be considered a virtual representation of an object, there is no bi-directional flow of data between the acquired volume and the object, and therefore it cannot be considered a Digital Twin under the original definition. A tomographic volume reflects the state of an object at the time that it was imaged, and any changes or processes that occur after imaging cannot be reflected in the digital representation of the object. Conversely, changes or edits made to the digital data cannot be accurately reflected in the physical object.
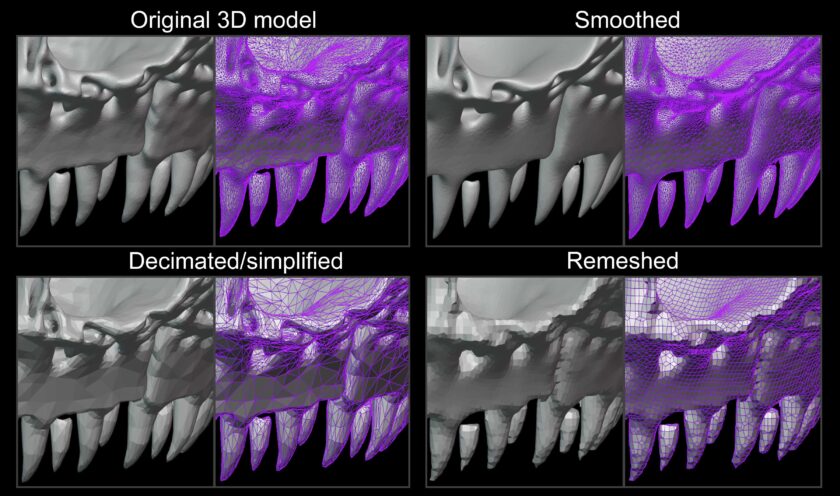
When it comes to derivatives of CT volumes, we move even further away from the concept of a Digital Twin as outlined above. During the process of producing 3D models, many decisions are made by the user that affect the resulting 3D model. Different CT data processing software can generate vastly different 3D models depending on their capabilities and surface defining algorithms. Results may also vary if the user decides to use an automated or semi-automated segmentation tool, as opposed to human interpreted and manually segmented structures. After they have been generated, most 3D models will then undergo various processes to make them suitable for downstream analysis and display. A model may be smoothed (and smoothing algorithms can vary across software), simplified/decimated, have topology deformed, edited or removed, or be entirely rebuilt (known as “remeshing”). While the end result may still be considered a representation of that object, and may suit the user’s needs and requirements for certain analyses, it is not a Digital Twin.
Instead, scientists often treat 3D reconstructions and surface models as hypotheses of the size, shape, and contours of the source material. Each CT user might produce a very slightly different surface based on the smoothing choices, decimation, and remeshing steps depicted in the figure below. To account for this “error”, we consider the outputs to be hypotheses of the 3D features of the original object. In this way we can compare hypothesized surface meshes, for example, with the understanding that they are a representation of real world objects. These representations aren’t twins, but they do provide important details about size, shape, and internal features to address scientific questions.
In all fields of science, poorly defined terms have reduced utility and make them weak choices to represent scientific concepts (see Wake 1994). Consequently, we should proceed with using appropriate and precise terms for specifying what we mean in a scientific context, and use caution when encountering apparent “buzz words”, like Digital Twin.